When will tracking data have its xG moment?
Five years ago, I wandered into my first Stats Perform Pro Forum.[1] The Pro Forum, if you're not familiar with it, is like Davos for people who read Opta data feed specifications instead of public policy documents. A swarm of analysts, and increasing numbers of 'Head of Analytics'-es, get invited by the data provider to see talks that push the boundaries of what we do with data.
The 2017 Forum was, I think, the start of tracking data being The Thing People Talked About. The buzz around it was like the buzz around NFTs now, only less riddled with scams. The hope was that it would change the game for analytics, especially around defending.
Now, I wouldn't say that tracking data hasn't had an impact in the five years since, but nor has it produced an impact like expected goals. There hasn't been a widespread, noticeable change in the way the game is played that can be attributed to it. So, why is that? Let us count the ways.
1. Secrecy
The most obvious and most frustrating one. Expected goals as we know it was more or less created in public, by bloggers and loudmouth tweeters. The point at which long-range shots started falling away is also, coincidentally, about the point the shouting about xG started (around 2014 and 2015).
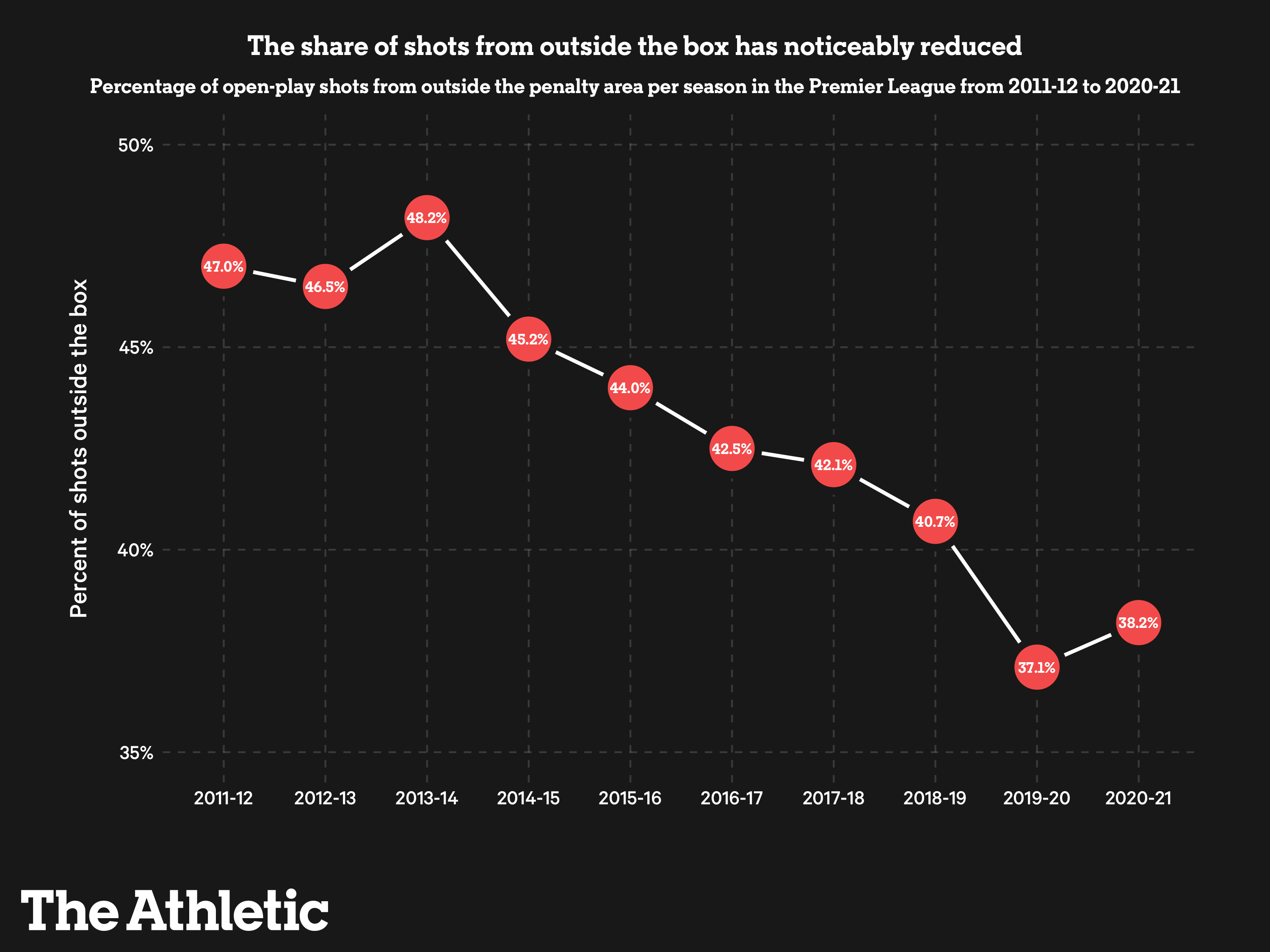 |
Above chart is from a recent piece on The Athletic about the change to shot locations in the Premier League.
Since then, smart people have been snapped up by clubs or assorted NBOs (Non-Balling Organisations) like data providers, agencies, or software companies. Work happens behind closed doors, save for the occasional Sloan conference paper (usually involving people from Barcelona, with their Innovation Hub, or Swedish team Hammarby, with their David Sumpter).
This is obviously particularly annoying for people publicly writing about football analytics, but the thing with xG was that every team could put it into action. You didn't need an analytics research department to read a blog. You just needed to know where the blog was and think it was worth paying attention to.[2]
2. Football is hard
It's really easy to tell whether one type of shot is better than another. But when you get further than, say, 25 yards from goal everything just kind of merges into a shrug. I like referring to Thom Lawrence's phrase when thinking about this, 'the Trough of Meh'.[3]
The value that came from knocking together an expected goals model was simple and relatively big. 'Scoring from long-range shots is way less likely than you think, and gives the ball to the opponent - do it a little less'; 'this player who scored a lot of goals was on a freaky hot streak, think hard about signing them'.
Early days of analytics also highlighted the value of through-balls and cut-backs, things which everyone probably already knew were valuable, but didn't seem to train specifically for as happens now. (Although this is more of a Pep Guardiola influence than an analytics influence).
The public work on tracking data has often been about things like pitch control models (for more on those, read this), which seem to naturally lean towards learning about build-up phases of play. They're simply harder to be punchy about than shooting shots.
3. The technical problems
Long-time analyticsers can probably skip this section, but it's worth repeating. In regular event data each action that happens on the pitch (shots, tackles, passes) are a single row, like in a spreadsheet. In tracking data, a single row is usually around one twenty-fifth of a second of action. A five-pass move taking five seconds will take up five rows of event data; it'd take 100-125 rows of tracking data.
This mass of data raises the barrier to entry, unless someone has created a product to do the hard work for you. You can't do much with it as a beginner coder; your database infrastructure will need to be better; your computer modelling needs to seriously take into account processing speed. You probably need to think about physics.
Data is also less available. There are some free datasets out there, like Metrica Sports' but you can't systematically scrape entire seasons' worth of data in an evening like it would be possible (or so I've heard) to do with event data.[4]
It's all very well having some games of data, but it really limits what you can make out of it. This 2017 article on how players outperform their xG (or don't) by Marek Kwiatkowski had a sample of nearly 200,000 shots and still had big margin-of-error bars.
4. All factors are important
With higher barriers to entry for a public mass of amateur analysts, less data to work with, and therefore the bulk of the work happening behind closed doors, it's no surprise that nothing's gone boom.
...
But maybe I'm wrong. Maybe there has been a comparable explosion in understanding of the game, that's been applied to tactical plans, and it's the first factor, the secrecy, that's keeping it from public knowledge.
The number of people who've worked with tracking data is growing every year too. And, even amongst the shrouds of secrecy, there are an increasing number of teams of people working with it. There are the stalwarts, at Liverpool and Barcelona's Innovation Hub. Manchester City/City Football Group have expanded their operation (as written about previously). There are more tracking data providers than before. There are big consultancies like the Analyticses, Zelus and Blue Crow (also written about previously).
The other thing is that, even if the technical barrier isn't as high, the pool of people working on this stuff isn't necessarily smaller than when xG was created. Football analytics is far less niche now.
So maybe I've been asking the wrong question. Maybe the question isn't "when will tracking data have its xG moment"; maybe it's when will we hear about it.
Footnotes
[1] "...my first Stats Perform Pro Forum." || Back then Stats Perform was still Opta, but I've referred to it by its current name throughout for ease of writing.
[2] "You didn't need an analytics research department to read a blog. You just needed to know where the blog was and think it was worth paying attention to." || I think we're beginning to get to something like this with tracking data. This research paper from the aforementioned Barcelona and Hammarby demonstrates that pitch control models can be used to help players with their positioning choices. Projects like this tactics board app from Joris Bekkers, which includes a pitch control model function, could offer coaches the chance to use 'tracking data' without having tracking data.
You could re-create a situation from a game in an app like that, using the pitch control function to demonstrate how the balance can change if positions are changed by just a few yards. I'm not sure if this would lead to something as blatantly clear as the xG effect on long shots, but it'd be a way to spread the influence of tracking data.
[3] "...the Trough of Meh" || The other side of this trough is how risk increases sharply as you get close to your own goal. The midfield is a place of very little immediate risk and very little immediate reward. Even when looking at non-immediate risk and reward there's usually not much going on.
[4] "...you can't systematically scrape entire seasons' worth of data...like it would be possible...to do with event data" || You could try and create your own tracking data. This 2020 Sloan analytics conference paper from Neil Johnson gives a bit of a template (although I can't say I've tried it myself), but I doubt it would be a speedy way of getting your hands on it.